-

Adversary Simulation
Our best in class red team can deliver a holistic cyber attack simulation to provide a true evaluation of your organisation’s cyber resilience.
-

Application
SecurityLeverage the team behind the industry-leading Web Application and Mobile Hacker’s Handbook series.
-

Penetration
TestingMDSec’s penetration testing team is trusted by companies from the world’s leading technology firms to global financial institutions.
-

Response
Our certified team work with customers at all stages of the Incident Response lifecycle through our range of proactive and reactive services.
VoIP Attacks: Skype Proof of Concept Released
In October 2013, Dominic Chell and I (Shaun Colley) presented our research and proof-of-concept tool for traffic analysis of encrypted VoIP streams. We focused on Skype as a case study.
Our main attack involved the use of Profile Hidden Markov Models to detect known phrases in encrypted VoIP conversations when Variable Bit Rate (VBR) codecs are being used with length-preserving ciphers (i.e. AES in CTR mode). You can find the full whitepaper here:
The attack works by first breaking down a stream of encrypted VoIP packets into a sequence of payload lengths – i.e. the data portion of the UDP packet lengths. Because of the nature of using VBR codecs with length-preserving encryption, the sequence of packet lengths observed in a VoIP packet stream will be similar (but not identical) each time an identical chunk of audio is encoded by the software.
Our attack revolves around ‘training’ a Profile HMM with many payload length sequences observed when a particular phrase is encoded and transmitted by Skype. Once trained, payload length sequences observed “on the wire” can be tested against the constructed PHMM. Payload length sequences are tested against the PHMM by obtaining the log-odds score for the sequence being emitted by the PHMM; this score is then compared with a pre-determined scoring threshold. If the log-odds score meets or exceeds the scoring threshold, we have a hit – a possible utterance of the known phrase, and otherwise we have a miss – probably not an utterance of the phrase.
We have demonstrated this attack by development of a proof-of-concept tool we have aptly named ‘skypegrep’. Skypegrep’s standard usage is quite simple – it takes two pcap files as command line arguments:
1) a training data pcap – this file should be a packet dump from a (Skype) conversation of a known phrase being continually repeated, with silent intervals in between each utterance.
2) test pcap – this file should contain one or more speech phases from a Skype packet dump. Each speech phase will be scored against the PHMM for possibility of being the known phrase.
We have included a sample training data pcap file – darkSuit.pcap. This pcap contains around 400 instances of the phonetically rich phrase “We had your dark suit in greasy wash water all year” being spoken by the same speaker.
For info on how to record some training data, see our whitepaper. A good place to start for testing purposes would be packet captures of many utterances of a certain phrase by the same speaker or speakers with very similar accents, with each utterance separated by 5-10 seconds of silence. The more utterances the better. Environments with minimal background are ideal. Two systems running Skype are necessary to set up a conversation over which the training audio is played.
Skypegrep’s standard usage syntax is as follows:
sh-3.2# java -jar -Xmx3g skype.jar train <trainingData.pcap> <test.pcap> <scoreThreshold>
‘scoreThreshold’ should be determined on a per-model (i.e. per-phrase) basis to give low false positive and low false negative rate. One way to determine a sensible figure for the scoring threshold is to test several pcaps which are known to feature the utterance in question against the PHMM. For the sample data recorded, a reasonable scoring threshold is 185.0.
So, to test against a file called ‘wrong.pcap’, we may run skypegrep as follows:
sh-3.2# java -jar -Xmx3g skype.jar train darkSuit.pcap wrong19.pcap 185.0
*** parsing training data pcap file
*** removing silence & noise from training data
*** number of silent & noisy phases removed: 479
*** parsed training data file (darkSuite.pcap) successfully.
*** number of training sets: 402. average training sequence length: 147
*** alphabet size: 95
*** training Profile HMM
*** profile HMM trained..
*** parsing test sequence(s) pcap file..
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
***** SEQ 1:
*** test sequence is 281 pkts long
*** scoring threshold = 185.0
*** calculated log-odds of sequence for trained model = 173.40509252621132
[***] PROBABLY NOT A MATCH FOR KNOWN PHRASE
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-
**** matches in file: 0 / 1
enter another filename:
The tool also offers a ‘plotting mode’, which allows payload length sequences to be plotted graphically vs. time. This feature was particularly useful during our research for comparing the “shapes” and features of payload length sequences in encrypted VoIP streams. Moreover, use of the plotting feature allows one to visually ascertain that identical or similar utterances do indeed result in similar plots each time. For syntax is:
sh-3.2# java -jar -Xmx3g skype.jar plot <data.pcap> <pktOffset> <numPkts>
So, using the included sample data:
sh-3.2# java -jar -Xmx3g skype.jar plot darkSuit.pcap 500 1000
*** extracting training data from pcap file
*** removing silence
*** number of silent phases removed: 2
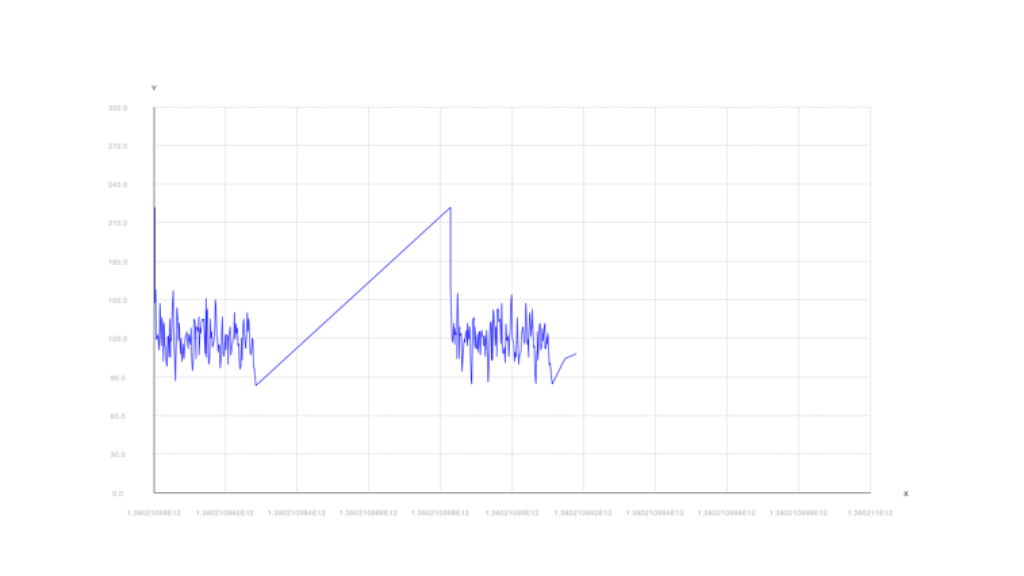
Notice the similarity of the two plots – which makes sense, since they are simply a different instance of the same utterance, by the same speaker. Compare this with two plots of utterances of completely different phrases:

Our tool makes use of the BioJava library (older versions) to implement its Profile Hidden Markov Model code, and uses SJPCAP to help with parsing pcap files. jmathplot is used for graphical plotting. We have included these libraries in this bundle, in the ‘lib’ directory.
As explained in the whitepaper itself, the quality of results in terms of low false positive and false negative rates depend very strongly on the quality of training data used. Strong variances in accent are likely to affect results, as is training data collected in noisy environments. With a large amount of high quality training data, accuracy of results will also differ with the phrase being spoken, but for phonetically rich phrases, true positive rates of around 80-90+% and false positive rates of around 10-20% can be expected.
Like all experimental proof-of-concept tools, our code has its limitations. There are potentially several improvements that could be made to improve results, but as a PoC and experimental tool, we hope this is useful and informative to the interested.
You can download the tool from our github page:
https://github.com/mdsecresearch/skypegrep